On Tuesday 9 January, some people met at the MIT Press offices in Cambridge to seed the Paged Media Open Source initiative: a suite of JavaScripts to paginate HTML/CSS in the browser for the purposes of exporting print-ready, or display-friendly, PDF from the browser. This project, launched by Adam Hyde (Coko Foundation, Shuttleworth Fellow), is based on community-led development and I was invited to work on it with Fred Chasen during the next few months. For this first meeting, I made a presentation about different Paged Media approaches and tools that already exist. This post in two parts is a version of that presentation.
A. Flow and layouts methods
Designing a book or a print-ready PDF requires that you think by pages. This is the major difference between formatting for the web and for PDF/Print. In a browser, we are able to implement a fixed height block with overflowing/scrollable content or automatic height block based on content. But for print/PDF, we need to be able to create pages of HTML content i.e. we need to be able to fractionate the content.
When a page has a fixed size, the content might not fit and might flow into the next page, making it tricky to ensure all pages will have a suitable amount of content, one after the other. We need to have an automatic flow of content into the page templates so the pages are filled by flowing content, with some specific rules “around” control of page elements (notes, running headers, page numbers, etc.).
Fortunately, there are some ways to provide this dynamic flow of content from one layout element to another, and in the following section, I focus on these different methods for paginated layouts.
But, first, let’s look at what we need to create a layout:
- A basic unit for paged media is the page spread: the left and right page are of the same size and typically are symmetrical to each other and are centered on the gutter. So, it’s important to setup a page structure with the page size and rules making a distinction between right and left pages. For professional print, we must add printer marks and bleed that will allow the printer to properly cut the publication before binding.
- For building a book, we need to add specific elements so that the reader can find his way around the book: a table of contents, running headers and footers, page numbers, cross-references, index, and so on. However, these elements make little sense on the web and don’t exist in HTML content. So when it comes to converting HTML to PDF/print, we’ll see that, in most cases, these elements have to be generated (by javascript or CSS).
- Similarly, for print design, it is necessary to size and position the content matching the function of the page. To do this in HTML pages, we need to apply CSS principles of vertical alignment, absolute position, float or exclusion, to the page elements.
Method 1: CSS Multiple columns
The CSS Multi-column Layout Module, as its name suggests, enables a flow of content within several columns of equal widths, with a gap and a rule between them. The height of the columns is defined by the elements to which the property is applied.
This “flowed” model is implemented in epub.js to paginate content and is recognised in many web browser rendering engines and in most modern ePub app and frameworks such as iBooks.
Basically, each page is a column and an iframe moves along the main box to select the content we see. The margins are defined by floating elements and running headers are added by JavaScript. For now, this layout method works fast because there is no need to calculate content splitting by JavaScript. However, it’s a crude method with the need for a lot of adding/hacking to arrive at a correct result of print layout.
Method 2: EPUB Adaptive Layout
EPUB Adaptive Layout is a CSS-based standard proposed by the International Digital Publishing Forum to define a model for template-based adaptive paginated layouts to be achieved on the fly.
This specification is in two parts: Page Layout and Adaptive Styling. Page Layout allows the definition of page masters in the CSS which contain a number of partitions (areas of the page where content from a particular flow can be displayed) and these partitions exist in the context of a particular page master. Page Layout also makes it possible to associate content with a specified partition, and to add specific styling to that partition. It also controls the process by which the EPUB reader will flow the content into the partitions. Adaptive Styling supports Page Layout and provides a means to turn styling on or off, based on conditions.
The distinction between left and right pages is made with options on the flow such as `-epubx-enabled: -epubx-expr(page-number % 2==0`
which activates or not the partitions for which this flow is called.
When rendering, pages are automatically created until flow(s) are exhausted.
Page number, running headers and notes are also partitions but each has particular flow options. For example, running headers are created by `-epubx-flow-option: static` - the element will be used until another element of the same stream with the same tag/class is found in the html.
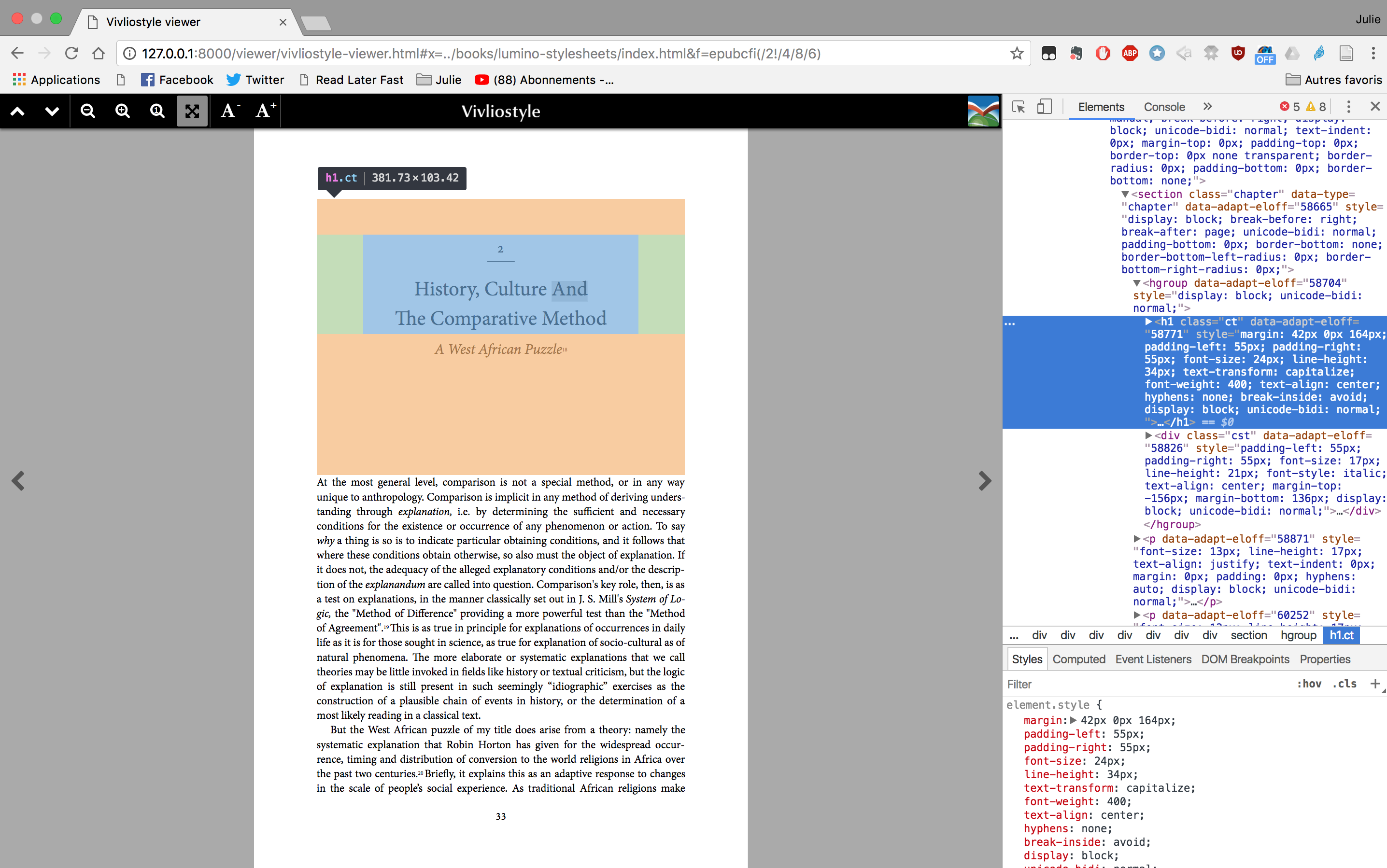
I have found only two “tools” that implement this specification: Adapt and Vivliostyle. Both of these tools rely on JavaScript-based implementation using a browser engine as a renderer, but Vivliostyle is more about print-ready output.
In my limited experience with Vivliostyle, it seems difficult to correctly manage multiple content flows, because of ambiguities in the standard or because the standard leaves room for interpretation and Vivliostyle implements it in an obscure way (there is at present no documentation about this tool). I will not write more on this method because, since the merger of the IDPF with the W3C, we can imagine that it will evolve to get closer to the proposals of the W3C (method 4). For now, you can read Julien’s post about Vivliostyle.
Method 3: CSS regions
CSS regions are very short specifications that allow the flow of content into a sequence of defined containers. (This is an equivalent to linking text boxes in InDesign.)
Page layouts with block containers are built in HTML before the content is flowed into them. After building, section(s) of content are associated in named flows and requested to flow into a set of defined blocks (region chain).
“A CSS Region is a block container that has an associated named flow. […] Content is placed into a named flow with the flow-into property. The content in a named flow is laid out in the region chain that is associated with this named flow using the flow-from property.” (W3C specifications). If the content overflows of the region chain, we need to add a region “manually” in the HTML.

To achieve sophisticated layouts, it’s possible to add multiple divs in one page (divs into div) and multiple nested flows.

It’s important to note that CSS regions allow you to dynamically flow content from one layout element to another, but do not specify how those elements are presented (we need to specify these with more CSS). Unlike Multi-Columns (or more recently Flexbox and Grids), CSS Regions are not a layout feature. They are a fragmentation feature that allows us to control or change the flow of content across containers. As Sara Soueidan writes, they define where content flows and not how.
In addition, we need to add specific HTML to build the layout and this requires the addition of non-semantic presentational elements. (A concern that the use of such elements is harmful and undesirable and a backward step is a big complaint about CSS regions.)
CSS Regions Module Level 1 is a working draft proposed. CSS was implemented during a time in Blink -webbkit- and in experimental features on Chrome but they both abandoned it few months ago. Currently, these features no longer exist in browsers but a javascript implementation has been developed by Fremy Compagny.
Book js and CaSSius use or have used this method. Basically, they use JavaScript loops for added or removed pages (block containers in HTML), in function of the length of the content and for building running headers, page numbers, and other elements needed in books.
Method 4: CSS paged media (W3C)
CSS Paged Media Module is a CSS module that has been created specially to deal with printed and paged media and proposes some basic pagination control features. Currently, it’s a working draft dated 14 March (first version). It adds functionality for pagination, page margins, page size and orientation, headers and footers, widows and orphans, and image orientation. This module is extended by the CSS Generated Content for Paged Media Module that we’ll see in the last part of this post.
CSS page model describes the way a page model is used to partition a flow into discrete pages. A section of the HTML content is associated to a named page model in the CSS. The specific page layout will be applied when the element of the section is encountered in the DOM. So, you can have several different page models in a document. Unless you specify otherwise, page breaks occur only when the page model changes or when the content overflows the current page box. To otherwise force or suppress page breaks, it’s possible to use page-break proprieties. When rendering, pages are automatically created until all the content of the relative sections have been exhausted.
It works like this :
The page model specifies how a document is formatted within a rectangular area, called the page box, defined with the @page rule.
This rule lets you specify various aspects of the page model such as dimensions, orientation, margins, cropping, registration marks, and so on.
A page box consists of two types of area: page area and page margin boxes.
Page area
The page area is the content area of a page box. It is the space into which the HTML content will flow. When this content runs out of room, another page will be automatically created.
“The page area acts as a container for all the boxes generated by the root element and its descendants that are laid out within a given page box.” (W3C specifications)
There are some possibilities to layout the content in the page area : multicolumn, footnotes (for now, it’s not possible to move the note area in to any other place than page bottom) and the content can be moved by positioning and floating, but it’s limited (we see that in the second part of the post).
Margin boxes
The margin area of a page box is divided into 16 page-margin boxes, each with its own margin, border, padding, and content areas and called in the @page with rules such as @top-left, @bottom-right-corner, @left-middle, etc. (see all rules) By default, their sizes are determined by the margin of the page box. Page-margin boxes are typically used to display running headers, footers, page numbers and other content needed for a book but not normally present on a website, with this content generated by CSS.
Pseudo-class selectors
Another aspect of the page model is that it defines pseudo-class selectors for added proprieties on certain pages of a page model. We typically need to have different margins on the left and right pages, so, we can use these selectors to define this different margin sizes for pages in the same section. The different pseudo-class selectors proposed by W3C are `:first`, `:left`, `:right` and `:blank`.
Tools such as Prince and PDF reactor add the pseudo-class `:nth()` that takes a function of the form An+B for selecting a specific page. Prince also proposes to create page “group” of consecutive elements belonging to the same named page but with logically separate structures (such as individual chapters). Like this, it’s possible to apply `:first` selector to the first page of each chapter that has the same page model.
With this CSS paged media method, all the layout of the PDF/print is done in CSS and you don’t need to add any structural elements in HTML or by usuing JavaScript. Prince, PDF reactor, AnthennaHouse, Weasyprint use this method, based on W3C specifications with some added proprietary specifications.
There is also a fifth bonus method used by PDF reactor: a combination of CSS region and CSS Paged Media.
B. Type of tools
It is possible to further separate these tools that propose different paginated layout methods into two types: JavaScript tools in the browser and standalone tools.
JavaScript tools in the browser
Tools such as book.js and CaSSiuS are essentially using javascript to polyfill CSS regions with browsers simulating PDF rendering. During the meeting at MIT press, Fred Chasen called this “retrofill” of CSS region. The pages are displayed on computer screens as printed output simulations and the PDF is generated with the rendering engine of the browsers.
With these tools, there is the possibility to access and use browser development tools for making on the fly modification of styling and positioning. There is no need to generate the PDF to see the result of the code. “Hacks” are possible to create complex layouts but that requires developments in JavaScript.
Standalone tools
Standalone tools such as Prince, PDF reactor and AntennaHouse are proprietary software programs for generating PDF in the command line or with a basic graphical interface. They implement their own rendering engine for PDF. To see the result, you have to generate the PDF with each change, which is a waste of time. Making special manual layout refinements such as widows and orphans is time-consuming. There are no element inspection tools to help debug. It’s not possible either to use JavaScript to add features as we can only use what the tools make available.
For now, it’s only these tools that integrate CSS paged media specifications more or less completely with additional proprietary features that are not part of the related standards. But these specific extensions make interoperability hard.
Two interesting exceptions
I found two interesting exceptions to this typology : Vivliostyle and Weasyprint.
Vivliostyle is a tool used in the browser but is not a simple simulation of PDF as it offers a more complex display interface with the possibility to zoom or have the page in a spread. It’s based on the EPUB Adaptive Layout specifications. However, Vivliostyle doesn’t use all the possibilities of the browser because it’s impossible to add JavaScript and it doesn’t take into account some CSS features that are implemented in browsers (such as Flexbox or clip-path, for example).
Weasyprint is a visual rendering engine written in Python and is usable in command line. It’s based on various libraries but not on a full rendering engine such as WebKit or Gecko. The WeasyPrint Navigator is a very limited web browser, running in your web browser, it only shows the PNG output from WeasyPrint with overlaid clickable hyperlinks. There is some effort to implement a list of W3C specifications but these don’t support enough features to be interesting.
In the next part of this post, we’ll identify additional features we need for making sophisticated layouts and the drafts or propositions currently being developed. We also see what the W3C proposes (or not) for specific styles and content elements needed to make a book: generated content, color management, baseline and typographic matter, and so on.
Hi Julie Blanc, How are you.I want to count dynamic generated pages from HTMl to PDF using css or JS whatever.Is there any solution for this i have tried in many ways but unable to get the result as same.Like this.counter-increment: page ;content: “page ” counter(page) ” of ” counter(pages);
Hi ! If you use pagedjs, this specification is implemented, you don’t need to increment the `counter(page)` or the `counter(pages)` to use it. You just need to add them to a margin box.
Thank you for your feedback!
Julie
Good morning Julie – and thanks for this very useful overview of current options. I shall be reading it again (several times!) to try and understand them,since this is a new area to me.