I can’t remember when Adam Hyde first suggested to me that CSS regions might be a viable way to produce PDFs for scholarly communications but it seemed like a good idea at that time and, I think, it still does. CaSSius is my implementation of that idea.
To back up a bit, at the moment in scholarly communications, the production stage usually involves creating a PDF and XML copy in tandem, perhaps using a tool like eXtyles and a process involving Adobe InDesign.
Previous attempts to go from the XML to the PDF (rather than from the Word document to the PDF and XML in parallel but different stages) have often focused around a technology called FOP (Formatting Objects Processor). FOP, though, is discontinued. It’s also virtually impossible to find or hire developers who can use it.
There is, though, another potential way. CSS Regions is an experimental technology that allows web designers to control the flow of text between different specified “region” sizes in a web browser. What we could do, though, is to create A4-size regions (or “pages”) and flow text between them. When we then use the “print to PDF” function of a browser (or a command-line tool such as wkhtmltopdf) what we would get would be… A4 PDFs. If we could get in one bound from JATS XML to PDF through this pipeline, we’d have a true XML-first workflow.
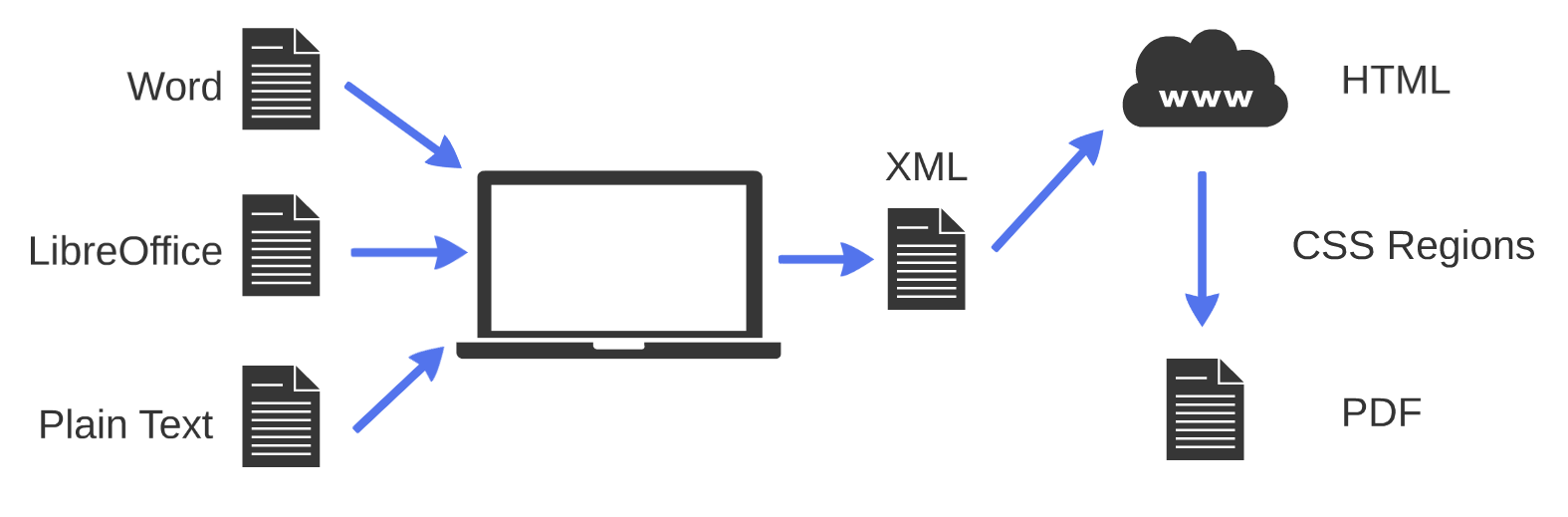
Illustration shows an XML-first workflow
There’s one slight snag, though. It turns out that CSS Regions is not well supported by current browsers. It is also unclear as to whether it ever will be. Fortunately, François Remy has created a Javascript implementation of CSS Regions support that can be plugged into any web page. I’ve made some slight modifications to the version of this in CaSSius for performance purposes.
So, here’s what CaSSius does:
- when a user runs the JATS conversion script (cassius-import), the preprocessor formats the citations and creates an HTML document in a mode that the front-end part of CaSSius can display;
- when the web page is loaded, CaSSius creates a default layout of 50 A4 pages and flows the user’s content between the pages;
- once the layout engine has completed its work, the pagination engine checks whether there are existing blank pages at the end of the document and sequentially removes them. If there are no blank pages, CaSSius adds another 50 pages and begins the layout engine portion again;
- once the layout and pagination engines have finished their work, the user can press “print” in the browser (or the command line tool can output its fine) and, with any luck, we have a nice PDF.

At present, the major challenge that we need to overcome is awkward page breaks. There are a few areas here where a heading comes immediately before the next page. I’d also, really, like to overcome the command-line dependencies on Saxon and Java. It would be really great if it were possible to point the web page at a JATS file stored online and do all the conversion in the browser. The other feature that we’d love to implement is an easy way to tweak the XML so that we can specify where line-breaks should fall.
In 1998, I did this with Framemaker. Fun times.
More recently, I’ve done this with the python package xhtml2pdf, whose github repo now says “Use Weasyprint” which appears to have a lot of the functionality you’re hoping for.
You have to do JATS->HTML for web; makes sense to use the same toolchain for print.
hey Eric,
Weasyprint is pretty interesting and we are hoping to get some posts about it. Would you be interested in writing something?
I just came across your website and it is perfect for where I am right now. I handle 2 online medical journals and work with JATS files. I am trying to find the best and most cost effective solution for going from XML to PDF. We are currently typesetting everything by hand in Indesign, but it takes a lot of time and money to do. I have been building a PHP library that parses the XML into HTML for various stages of the process, but I really want to start working on a workflow that automates most of it. I’ve also been messing around with converting to markdown and using pandoc to convert. I am wondering if you have any suggestions for me as you seem to be in the thick of it all. I am really good with CSS so it is very appealing to me to go this route. Thank you for the great articles!
I’m really looking forward to seeing what CaSSius, Vivliostyle and similar open-source in-browser layout engines can do. For the demanding book-publishing PDF layouts we do, we use PrinceXML, which is proprietary. It is excellent, so it’s worth checking out, but it’s also important to support open-source alternatives in the meantime, so that one day we’ll all have FOSS options with matching features.
We welcome contributions which focus on creating beautiful ebooks in the browser using HTML.